Member-only story
How to Build a Lossless Data Compression and Data Decompression Pipeline
A parallel implementation of the bzip2 high-quality data compressor tool in Python.
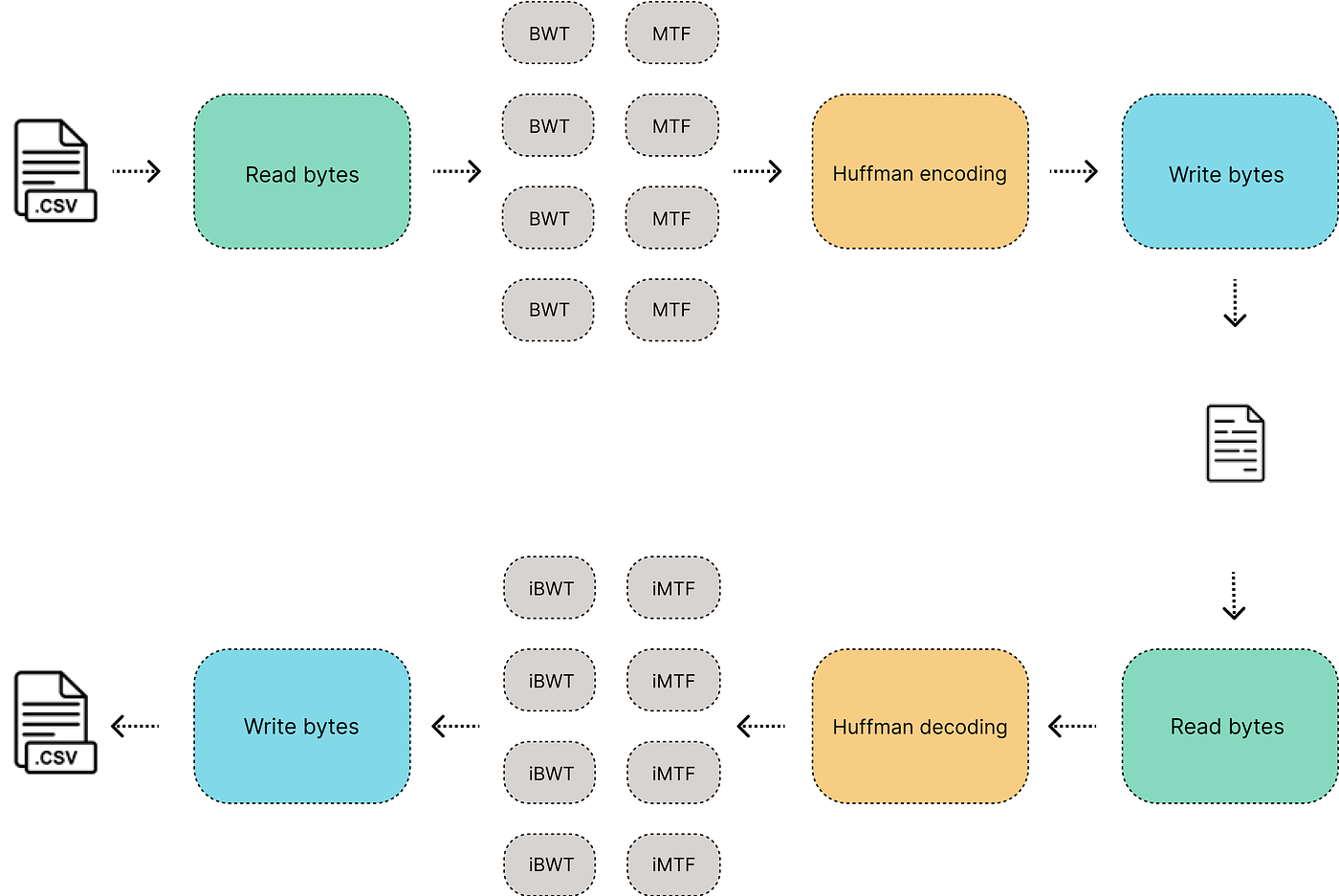
The image above shows the architecture of a parallel implementation of the bzip2 data compressor with python, this data compression pipeline is using algorithms like Burrows-Wheeler transform (BWT) and Move to front (MTF) to improve the Huffman compression. But for now, this tool only will be focused on compressing .csv files and could be modified to process other files in tabular format.
Check the repo here:
The need for compression
When we talk about computation time we are also talking about money, data compression represents the most appropriate economic way to shorten the gap between content creators and content consumers, compressed files are obviously smaller and it is necessary to less money and time to transfer them and cost less money to store them, content creators pay less money to distribute their content, and content consumers pay less money to consume content. On the other hand, companies in all sectors need to find new ways to control the rapidly growing volume of their heterogeneous data generated every day, data compression and data decompression tools are related as one of the most viable solutions to these problems. In fact, data compression and decompression techniques are the DNA of many famous distributed systems and part of their success is due to the proper use of these techniques.
Contextual Data Transforms
Modern data compression tools and techniques are not based only on the use of a compression algorithm, in fact, the use of this is part of the final stage of a whole data compression pipeline, but before reaching the last one, there is a stage called contextual transformations that which is responsible for rearranging the sequence of symbols in the dataset, so, they will be more sensitive to statistical compression…

