Member-only story
Working with large CSV files in Python from Scratch
5 Techniques
12 min readDec 21, 2022
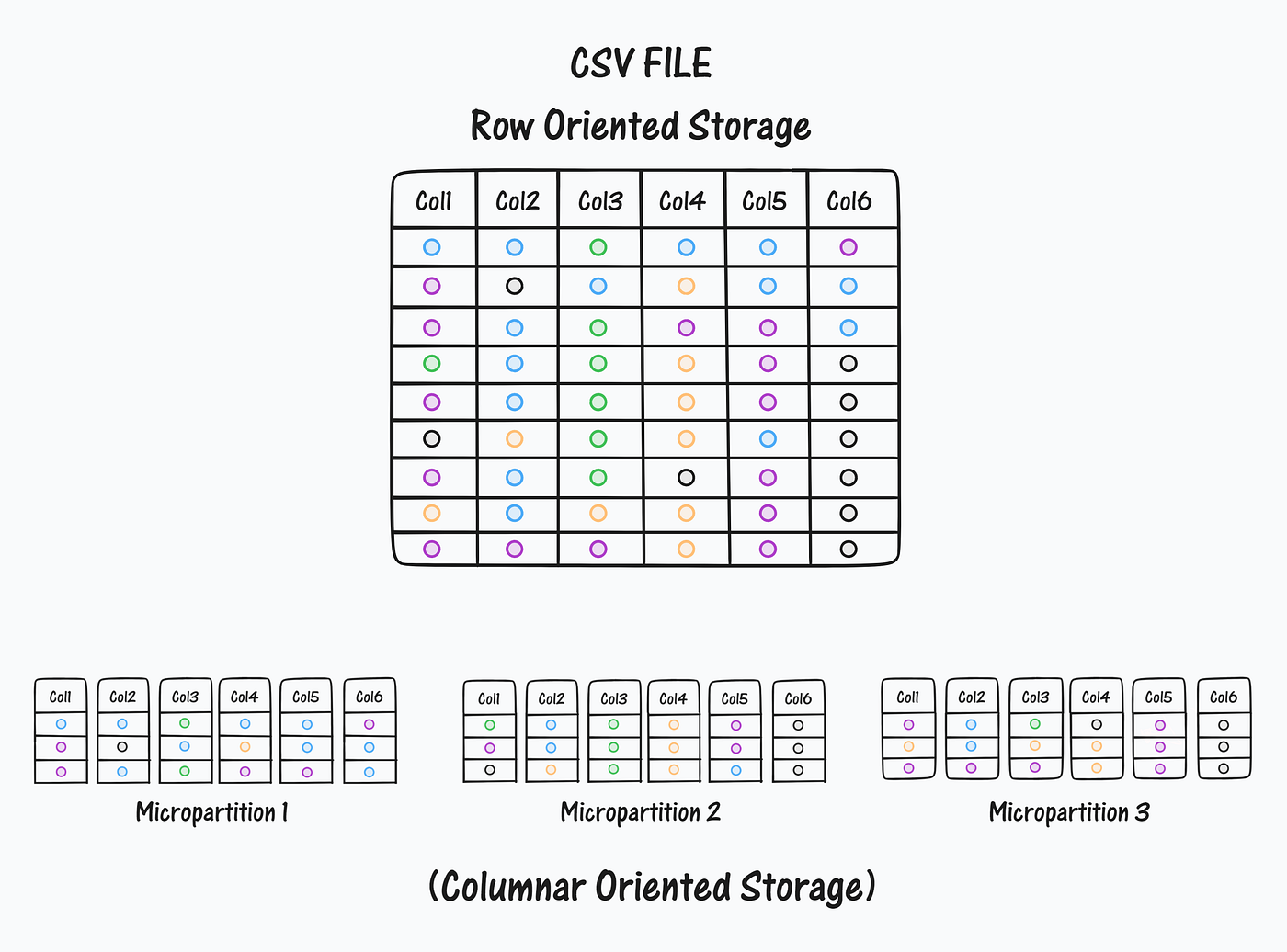
I assume you have already had the experience of trying to open a large .csv file on your computer and it stopped working to the point of having to restart it. It is obvious that trying to load files over 2gb into memory is still an extremely heavy task for current computers. This article explains and provides some techniques that I have sometimes had to use to process very large csv files from scratch:
Estimate count of rows
Knowing the number of records or rows in your csv file in advance can help you to improve the partitioning strategy, or division of the file. The code below can help you estimate the number of records or rows contained in a very large csv file:

mport mmap
import os
class Csvnrows(object):
@staticmethod
def estimate_csv_rows(filename, header = True):
count_rows = 0
with open(filename, mode="r", encoding = "ISO-8859-1") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as map_file:
buffer = map_file.read(1<<13)
file_size = os.path.getsize(filename)…